Benchmark
Environment configuration
OS: Red Hat Enterprise Linux Workstation 7.9 (Maipo)
CPU: 8x Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
GPU: GeForce RTX 2080 8G
Python: 3.6.8
Python package version:
numpy==1.19.5
opencv-python==4.5.5.64
mpi4py==3.1.3
numba==0.53.1
taichi==1.0.0
Problem size vs backend
To run and get the time spend:
$ fpie -s $NAME.png -t $NAME.png -m $NAME.png -o result.png -n 5000 -b $BACKEND --method $METHOD ...
The following table shows the best performance of corresponding backend choice, i.e., tuning other parameters on square10/circle10 and apply them to other tests, instead of using the default value.
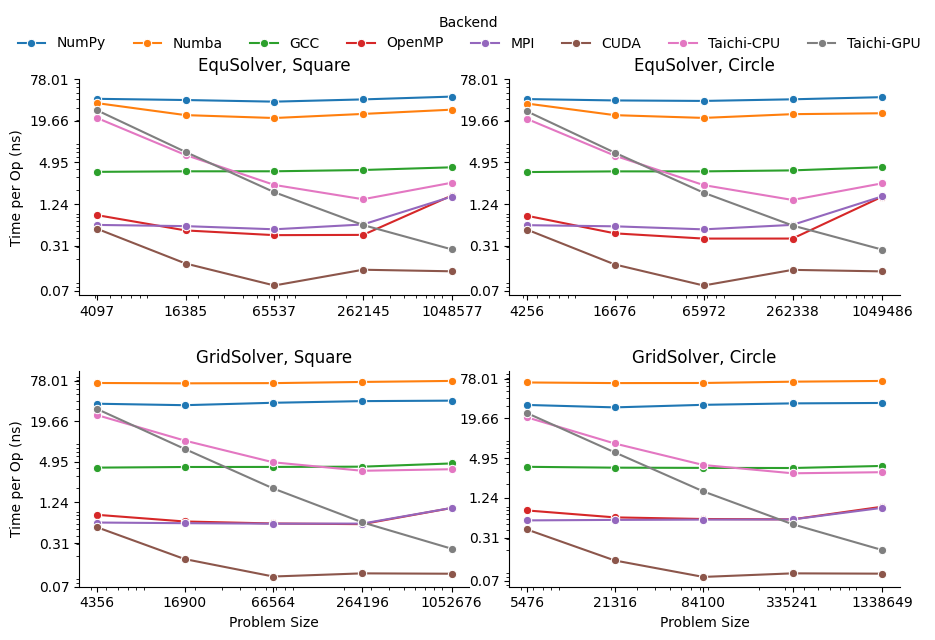
The above plots are generated by per-pixel operation time cost.
EquSolver
The benchmark commands for squareX and circleX:
# numpy
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b numpy --method equ
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b numpy --method equ
# numba
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b numba --method equ
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b numba --method equ
# gcc
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b gcc --method equ
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b gcc --method equ
# openmp
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b openmp --method equ -c 8
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b openmp --method equ -c 8
# mpi
mpiexec -np 8 fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b mpi --method equ --mpi-sync-interval 100
mpiexec -np 8 fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b mpi --method equ --mpi-sync-interval 100
# cuda
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b cuda --method equ -z 256
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b cuda --method equ -z 256
# taichi-cpu
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b taichi-cpu --method equ -c 8
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b taichi-cpu --method equ -c 8
# taichi-gpu
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b taichi-gpu --method equ -z 1024
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b taichi-gpu --method equ -z 1024
EquSolver |
square6 |
square7 |
square8 |
square9 |
square10 |
|---|---|---|---|---|---|
# of vars |
4097 |
16385 |
65537 |
262145 |
1048577 |
NumPy |
0.8367s |
3.2142s |
12.1836s |
52.4939s |
230.5375s |
Numba |
0.7257s |
1.9472s |
7.0761s |
32.4084s |
149.3390s |
GCC |
0.0740s |
0.3013s |
1.2061s |
5.0351s |
22.0276s |
OpenMP |
0.0176s |
0.0423s |
0.1447s |
0.5835s |
8.6203s |
MPI |
0.0127s |
0.0488s |
0.1757s |
0.8253s |
8.3310s |
CUDA |
0.0112s |
0.0141s |
0.0272s |
0.1835s |
0.6967s |
Taichi-CPU |
0.4437s |
0.5178s |
0.7667s |
1.9061s |
13.2009s |
Taichi-GPU |
0.5730s |
0.5727s |
0.6022s |
0.8101s |
1.4430s |
EquSolver |
circle6 |
circle7 |
circle8 |
circle9 |
circle10 |
|---|---|---|---|---|---|
# of vars |
4256 |
16676 |
65972 |
262338 |
1049486 |
NumPy |
0.8618s |
3.2280s |
12.5615s |
52.7161s |
226.5578s |
Numba |
0.7430s |
1.9789s |
7.1499s |
32.1932s |
132.7537s |
GCC |
0.0764s |
0.3062s |
1.2115s |
4.9785s |
22.1516s |
OpenMP |
0.0179s |
0.0391s |
0.1301s |
0.5177s |
8.2778s |
MPI |
0.0131s |
0.0494s |
0.1767s |
0.8155s |
8.3823s |
CUDA |
0.0113s |
0.0139s |
0.0274s |
0.1831s |
0.6966s |
Taichi-CPU |
0.4461s |
0.5148s |
0.7687s |
1.8646s |
12.9343s |
Taichi-GPU |
0.5735s |
0.5679s |
0.5971s |
0.7987s |
1.4379s |
GridSolver
The benchmark commands for squareX and circleX:
# numpy
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b numpy --method grid
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b numpy --method grid
# numba
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b numba --method grid
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b numba --method grid
# gcc
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b gcc --method grid --grid-x 8 --grid-y 8
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b gcc --method grid --grid-x 8 --grid-y 8
# openmp
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b openmp --method grid -c 8 --grid-x 2 --grid-y 16
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b openmp --method grid -c 8 --grid-x 2 --grid-y 16
# mpi
mpiexec -np 8 fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b mpi --method grid --mpi-sync-interval 100
mpiexec -np 8 fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b mpi --method grid --mpi-sync-interval 100
# cuda
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b cuda --method grid --grid-x 2 --grid-y 128
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b cuda --method grid --grid-x 2 --grid-y 128
# taichi-cpu
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b taichi-cpu --method grid -c 8 --grid-x 8 --grid-y 128
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b taichi-cpu --method grid -c 8 --grid-x 8 --grid-y 128
# taichi-gpu
fpie -s square10.png -t square10.png -m square10.png -o result.png -n 5000 -b taichi-gpu --method grid -z 1024 --grid-x 16 --grid-y 64
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b taichi-gpu --method grid -z 1024 --grid-x 16 --grid-y 64
GridSolver |
square6 |
square7 |
square8 |
square9 |
square10 |
|---|---|---|---|---|---|
# of vars |
4356 |
16900 |
66564 |
264196 |
1052676 |
NumPy |
0.7809s |
2.8823s |
12.3242s |
51.7496s |
209.5504s |
Numba |
1.5838s |
6.0720s |
24.0901s |
99.5048s |
410.6119s |
GCC |
0.0884s |
0.3504s |
1.3832s |
5.5402s |
24.6482s |
OpenMP |
0.0177s |
0.0547s |
0.2011s |
0.7805s |
5.4012s |
MPI |
0.0136s |
0.0516s |
0.1999s |
0.7956s |
5.4109s |
CUDA |
0.0116s |
0.0152s |
0.0330s |
0.1458s |
0.5738s |
Taichi-CPU |
0.5308s |
0.8638s |
1.6196s |
4.8147s |
20.2245s |
Taichi-GPU |
0.6538s |
0.6505s |
0.6638s |
0.8298s |
1.3439s |
GridSolver |
circle6 |
circle7 |
circle8 |
circle9 |
circle10 |
|---|---|---|---|---|---|
# of vars |
5476 |
21316 |
84100 |
335241 |
1338649 |
NumPy |
0.8554s |
3.0602s |
13.1915s |
55.3018s |
224.0399s |
Numba |
1.8680s |
7.1174s |
28.1826s |
117.5155s |
481.5718s |
GCC |
0.0997s |
0.3768s |
1.4753s |
5.8558s |
25.1236s |
OpenMP |
0.0219s |
0.0670s |
0.2498s |
0.9838s |
6.0868s |
MPI |
0.0155s |
0.0614s |
0.2446s |
0.9810s |
5.8527s |
CUDA |
0.0113s |
0.0150s |
0.0334s |
0.1507s |
0.5954s |
Taichi-CPU |
0.5558s |
0.8727s |
1.6317s |
4.8740s |
20.2178s |
Taichi-GPU |
0.6447s |
0.6418s |
0.6521s |
0.8309s |
1.3578s |
Per backend performance
In this section, we will perform ablation studies with OpenMP/MPI/CUDA backend. We use circle9/10 with 5000 iterations as the experiment setting.
OpenMP
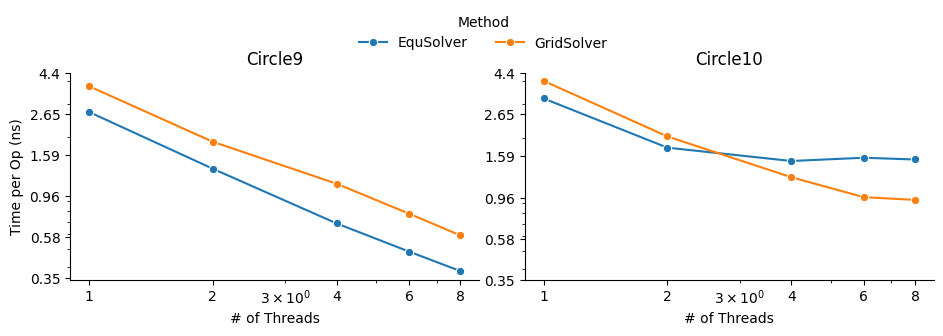
Command to run:
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b openmp --method equ -c 8
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b openmp --method grid -c 8 --grid-x 2 --grid-y 16
circle9 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
262338 |
262338 |
262338 |
262338 |
262338 |
EquSolver |
3.5689s |
1.7679s |
0.8987s |
0.6344s |
0.4982s |
circle9 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
335241 |
335241 |
335241 |
335241 |
335241 |
GridSolver |
6.2717s |
3.1530s |
1.8758s |
1.2955s |
0.9897s |
circle10 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
1049486 |
1049486 |
1049486 |
1049486 |
1049486 |
EquSolver |
16.9218s |
9.2764s |
7.8828s |
8.2016s |
8.0285s |
circle10 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
1338649 |
1338649 |
1338649 |
1338649 |
1338649 |
GridSolver |
26.7571s |
13.5669s |
8.2486s |
6.4654s |
6.2539s |
MPI
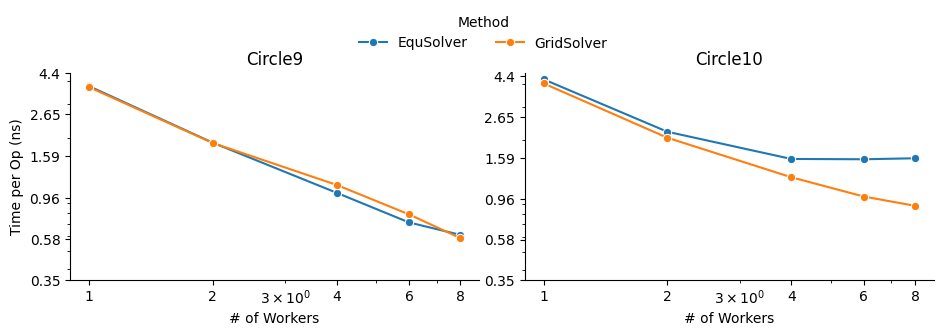
Command to run:
mpiexec -np 8 fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b mpi --method equ --mpi-sync-interval 100
mpiexec -np 8 fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b mpi --method grid --mpi-sync-interval 100
circle9 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
262338 |
262338 |
262338 |
262338 |
262338 |
EquSolver |
4.9217s |
2.4655s |
1.3378s |
0.9310s |
0.7996s |
circle9 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
335241 |
335241 |
335241 |
335241 |
335241 |
GridSolver |
6.2136s |
3.1381s |
1.8817s |
1.3124s |
0.9822s |
circle10 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
1049486 |
1049486 |
1049486 |
1049486 |
1049486 |
EquSolver |
22.1275s |
11.5566s |
8.2541s |
8.2208s |
8.3238s |
circle10 |
1 |
2 |
4 |
6 |
8 |
|---|---|---|---|---|---|
# of vars |
1338649 |
1338649 |
1338649 |
1338649 |
1338649 |
GridSolver |
26.8360s |
13.6866s |
8.3945s |
6.6107s |
5.8929s |
CUDA
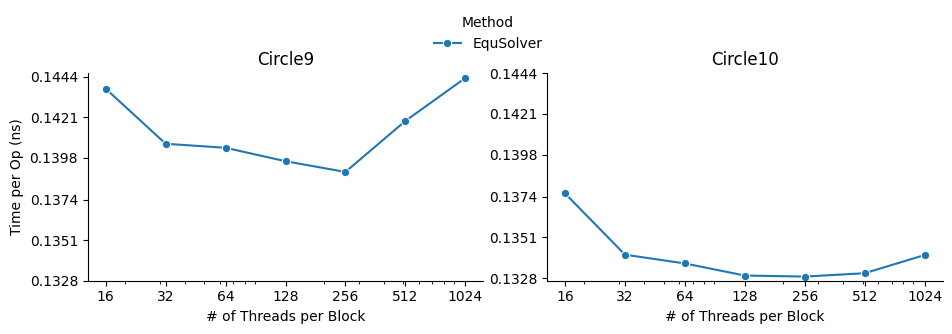
Command to run:
fpie -s circle10.png -t circle10.png -m circle10.png -o result.png -n 5000 -b cuda --method equ -z 1024
circle9 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
|---|---|---|---|---|---|---|---|
# of vars |
262338 |
262338 |
262338 |
262338 |
262338 |
262338 |
262338 |
EquSolver |
0.1885s |
0.1844s |
0.1841s |
0.1831s |
0.1823s |
0.1861s |
0.1893s |
circle10 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
|---|---|---|---|---|---|---|---|
# of vars |
1049486 |
1049486 |
1049486 |
1049486 |
1049486 |
1049486 |
1049486 |
EquSolver |
0.7220s |
0.7038s |
0.7012s |
0.6976s |
0.6973s |
0.6983s |
0.7037s |